AI
Knowing how to write effective prompts for text-to-video AI is less about “prompt engineering” and more about learning to brief a shot. A weak prompt says, “Make a product video.” A useful prompt tells the model what to show, how it should move, what the camera should do, what the lighting feels like, and what should stay out of the frame.
The model is not reading your mind. It is building a shot from the clues you give it. If you do not specify the camera, it guesses. If you do not specify the action, the clip may barely move. If you ask for five ideas in one short generation, you usually get visual noise.
The simplest way to improve your results is to treat every prompt like a miniature director’s brief: one subject, one action, one setting, one camera direction, one lighting style, and a few clear constraints.
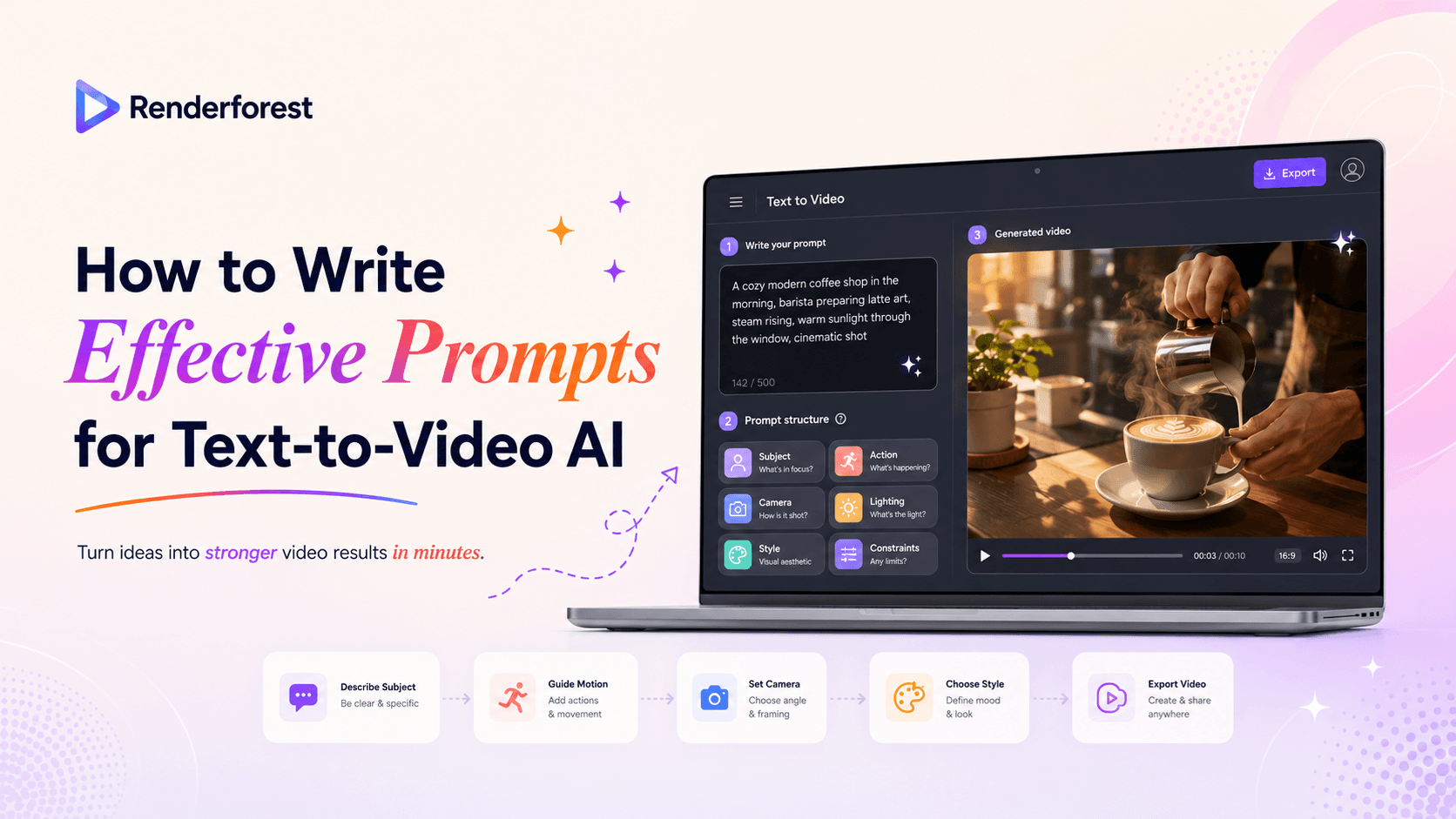
A strong text-to-video AI prompt usually follows this structure:
Subject + action + setting + camera + lighting + style + format + constraints
Here is the formula in plain English:
A complete prompt would look like this:
Create a 6-second vertical realistic product video of a ceramic coffee cup on a wooden café table near a rainy window. Steam rises slowly from the cup while the camera makes a gentle close-up push-in. Use warm morning light, shallow depth of field, soft reflections, and a calm premium café mood. No text, no hands, no logo, no sudden camera shake.
That works better than “coffee video” because it gives the model visual decisions to follow.
OpenAI’s Sora 2 Prompting Guide gives similar direction: describe the shot as if sketching it onto a storyboard, including camera framing, depth of field, action, lighting, palette, and distinctive subject details. Adobe’s Firefly video prompt guidance also recommends being descriptive, defining actions clearly, using camera angles and movement, adding context, and iterating.
Most weak AI videos come from prompts that are too vague, too crowded, or too abstract.
A text-to-video model does not know what “make it professional” means unless you translate that into visible choices. Professional could mean clean studio lighting, slow camera movement, neutral background, realistic materials, sharp focus, and restrained motion.
The model also struggles when the prompt asks for too much at once. A six-second video cannot show a full product story, three location changes, a testimonial, animated typography, and a dramatic ending without becoming chaotic.
A better prompt narrows the job.
The more visual your prompt is, the more usable the output becomes.
The best prompts are not long for the sake of being long. They are specific in the right places.
Think of the prompt as a shot brief with eight layers.
This is the core skill. Once you understand these layers, you can write better prompts for Sora, Veo, Runway, Pika, Luma, Firefly, Hailuo, Pixverse, MiniMax, Seedance, and multi-model tools like Renderforest.
The subject is the anchor of the video. If the model cannot identify the main subject immediately, the output often becomes messy.
Weak:
A beautiful lifestyle video with coffee and people and a nice café vibe.
Better:
A young barista places a white ceramic cappuccino cup on a wooden counter.
The second version tells the model what to focus on.
Good subjects are concrete:
Avoid making the subject too general:
Those can be part of the prompt, but they should not be the main subject.
A [specific subject] [visible detail] in/on/near [setting].
Example:
A matte black skincare bottle with a silver pump on wet black stone in a minimalist studio setting.
Video needs motion. A static prompt often produces a clip that feels like an image with slight movement.
Weak:
A luxury perfume bottle on a table.
Better:
A luxury perfume bottle slowly rotates as soft mist moves behind it.
The action should be simple enough for a short clip:
Do not overload one clip with five actions. If you need multiple actions, create multiple clips and edit them together.
[Subject] [does one visible action] while [secondary motion happens in the background].
Example:
A ceramic coffee cup sits on a wooden table while steam rises slowly and rain moves softly on the window behind it.
The setting gives the model context. Without it, the model guesses.
Weak:
A woman walking.
Better:
A woman in a beige coat walks through a quiet city street after rain, with reflections on the pavement and warm shop lights in the background.
Setting details help with mood, scale, realism, and lighting.
Good setting details include:
Set in [location], with [background details], [weather/time], and [surface/material details].
Example:
Set in a small independent bookstore at night, with wooden shelves, warm lamps, rain on the front window, and a quiet cozy atmosphere.
Camera direction is the quickest way to make an AI video feel intentional. “Slow push-in” instantly feels more premium than a static product shot. “Tracking shot” tells the model to follow motion. “Macro close-up” tells it to care about texture.
Google’s Veo prompt guide and Google Cloud’s Veo 3.1 prompting guide both focus on directing video with cinematic techniques, including camera, composition, style, and audiovisual direction. Runway’s Gen-4 Video Prompting Guide also describes generating controllable videos from an input image and text prompt, with clips created in 5- or 10-second durations.
You do not need film-school language. You only need a few useful terms.
Weak:
A cinematic product video.
Better:
A close-up macro shot of a skincare bottle, slow camera push-in, shallow depth of field, soft studio light.
[Shot type], [camera movement], [lens/focus detail if needed].
Example:
Close-up macro shot, slow push-in, shallow depth of field, focus on condensation droplets.
Lighting does a lot of the emotional work in video. It tells the model whether the scene should feel premium, cozy, dramatic, clinical, playful, or natural.
Weak:
A good-looking gym video.
Better:
A high-energy gym video with bright overhead lighting, fast movement, crisp shadows, and a bold motivational mood.
Useful lighting phrases:
Mood should support the visual goal:
Use [lighting type] to create a [mood] mood.
Example:
Use warm morning window light to create a calm, premium café mood.
Style tells the model what visual world to create. But style should not fight the rest of the prompt.
Weak:
Make it realistic, anime, cinematic, 3D, vintage, luxury, documentary style.
Better:
Realistic commercial product video with clean studio lighting and minimal background.
Useful text-to-video styles:
Use one dominant style per prompt. If you want to compare styles, run the same prompt several times with different style lines.
A prompt for a YouTube background clip is different from a prompt for a TikTok hook.
Useful format instructions include:
Weak:
Make a video for social media.
Better:
Create a 6-second vertical 9:16 video for an Instagram Reel opening shot.
Create a [duration] [aspect ratio] video for [platform/use case].
Example:
Create a 6-second vertical 9:16 video for a TikTok product hook.
Constraints tell the model what not to do. They also protect you from common output problems.
Useful constraints:
Constraints should be short. Do not write a long list of negatives that overwhelms the main instruction.
No [specific unwanted element]. Keep [important element] consistent.
Example:
No text, no logo, no hands. Keep the bottle shape consistent throughout the clip.
Use this as your base template:
Create a [duration] [aspect ratio] video of [specific subject] [main action] in [setting]. The camera [shot type + movement]. Use [lighting] to create a [mood] mood. Style: [visual style]. Keep [important element] consistent. Avoid [unwanted elements].
Example:
Create a 6-second vertical video of a matte black skincare bottle slowly rotating on wet black stone in a minimalist studio. The camera makes a close-up slow push-in with shallow depth of field. Use soft side lighting and subtle mist to create a premium luxury mood. Style: realistic commercial product video. Keep the bottle shape and label area consistent. Avoid text, hands, logos, flicker, and sudden camera shake.
The easiest way to understand prompt writing is to compare weak prompts with stronger versions.
Why it works:
Why it works: the prompt describes a single moment instead of asking the model to create a full commercial in one generation.
Why it works: real estate prompts need camera path, setting, light, and atmosphere. “Modern house” is not enough.
Why it works: it focuses on a visual hook instead of trying to show the whole workout.
Why it works: AI video models often struggle with exact interface text. This prompt asks for an abstract dashboard instead of precise copy that should be added later in editing.
Not every video prompt should be written the same way. Match the prompt to the job.
Product prompts should focus on consistency, material, texture, and camera movement.
Template:
Create a [duration] [format] product video of [product] on [surface/background]. The product [simple action or camera reveals it]. Use [lighting] to show [material/texture]. Camera: [shot type + movement]. Style: [brand mood]. Keep the product shape consistent. No text, no extra objects, no distorted label.
Example:
Create a 6-second vertical product video of a clear glass perfume bottle on a reflective black surface. The bottle slowly rotates as soft mist moves behind it. Use dramatic side lighting to reveal the glass edges and liquid color. Camera: close-up slow push-in. Style: luxury fragrance campaign. Keep the bottle shape consistent. No text, no hands, no distorted label.
Social prompts should focus on hook, format, pacing, and visual simplicity.
Template:
Create a [duration] vertical 9:16 video for [platform] showing [hook visual]. The scene should communicate [message] quickly. Use [camera movement], [lighting], and [style]. Leave space at the top/bottom for captions. Avoid [unwanted details].
Example:
Create a 6-second vertical 9:16 video for Instagram Reels showing a stack of fresh croissants being placed into a bakery display case. The scene should communicate a weekend bakery special quickly. Use warm morning light, close-up camera movement, and a cozy local bakery style. Leave space at the top for captions. No text in the generated video.
Cinematic prompts need stronger control over camera, lighting, and motion.
Template:
Create a [duration] [aspect ratio] cinematic scene of [subject] [action] in [setting]. Camera: [shot size, angle, movement]. Lighting: [lighting setup]. Mood: [emotion]. Style: [film style or visual genre]. Keep motion natural and avoid [problems].
Example:
Create an 8-second 16:9 cinematic scene of a cyclist riding through a wet neon-lit street at night. Camera: low-angle tracking shot beside the bicycle, slow motion, shallow depth of field. Lighting: blue and pink neon reflections on wet pavement. Mood: focused, urban, atmospheric. Keep motion natural and avoid distorted wheels or extra limbs.
Avatar prompts are different. The script matters more than cinematic visual detail.
Template:
Create a [duration] presenter-led video with [avatar description] speaking to camera. Tone: [tone]. Background: [setting]. Script: “[script].” Delivery should be [pace/emotion]. Keep eye contact natural and gestures minimal.
Example:
Create a 45-second presenter-led video with a friendly business coach speaking to camera in a clean office background. Tone: practical and calm. Script: “Here are three ways small businesses can use short videos to promote weekly offers.” Delivery should be clear, conversational, and not overly enthusiastic. Keep eye contact natural and gestures minimal.
Branded prompts should focus on audience, message, scene structure, and style. The final brand text should usually be added in editing, not generated inside the AI video.
Template:
Create a [duration] [format] branded marketing video for [audience] about [offer/message]. Scene 1: [visual]. Scene 2: [visual]. Scene 3: [visual]. Style: [brand style]. Lighting: [lighting]. Leave clean space for text overlays. Do not generate readable text or logos.
Example:
Create a 15-second vertical branded marketing video for small café owners promoting a new loyalty card. Scene 1: a customer receives a stamped card with a coffee. Scene 2: close-up of the card beside a cappuccino. Scene 3: a smiling customer leaves the café on a sunny morning. Style: warm, local, friendly, realistic. Leave clean space for text overlays. Do not generate readable text or logos.
You do not need advanced filmmaking vocabulary. These plain-English directions are enough for most AI video prompts.
Camera direction is especially useful in tools that support more controlled generation, such as Runway, Sora, Veo, and Firefly. Official guidance across these tools consistently points toward the same principle: describe the shot visually, not abstractly.
Some instructions make the output worse.
AI video models still struggle with precise readable text. If you need pricing, legal disclaimers, subtitles, a URL, a product name, or a CTA, add it in an editor afterward.
Weak:
Show the text “50% off this weekend only” on a sign.
Better:
Leave empty space in the upper third of the frame for a promotional text overlay.
A short AI video should usually do one thing well. If you need a full story, generate separate clips.
Weak:
Show a woman waking up, making coffee, driving to work, giving a presentation, and celebrating with coworkers.
Better:
Create a 6-second close-up of a woman pouring coffee into a travel mug in a bright kitchen before work.
A model can blend styles, but too many competing directions create muddy outputs.
Weak:
Photorealistic anime claymation documentary commercial.
Better:
Realistic handheld documentary-style social video.
Words like “professional,” “viral,” “beautiful,” and “high-quality” are not enough. Translate them into visible choices.
Instead of “professional,” write:
Clean studio lighting, centered composition, slow camera movement, minimal background, realistic product materials.
Instead of “viral,” write:
Fast visual hook, vertical 9:16 format, close-up subject, clear movement in the first second, space for bold captions.
Use constraints sparingly, but include them when they matter.
Once the basics work, use these techniques to improve consistency.
If the subject must stay consistent, start with a reference image when the tool supports image-to-video or character references. OpenAI’s Sora 2 guide discusses character references and longer, higher-resolution generation options, while Luma’s Dream Machine best practices cover visual references for consistent characters, objects, and styles.
Use reference images for:
Prompt example:
Animate this reference image into a 6-second product video. Keep the bottle shape, color, and label area consistent. Add a slow camera push-in, soft studio lighting, and subtle mist in the background. No text changes, no logo distortion.
For longer videos, write scene-by-scene prompts instead of one overloaded paragraph.
This gives each generation a clear job.
If a person appears in multiple clips, repeat the same identifying details.
Example:
A woman in her early 30s with shoulder-length curly black hair, round glasses, a beige trench coat, and white sneakers.
Use the same wording every time. Do not change “beige trench coat” to “tan jacket” in the next prompt unless you want the model to reinterpret it.
Do not ask the AI video model to do everything. Use the model for visuals. Use editing tools for final assembly.
Generate with prompts:
Add later in editing:
That workflow is more reliable and more professional.
Renderforest’s AI Video Generator lets users start with text, an image, or a script, choose a video model, style, and format, then generate visuals, voiceover, and scenes before refining and exporting the video. Renderforest’s Text to Video AI page also describes a workflow where users enter a script or idea, choose a style, and the AI creates a structured video draft with scenes, pacing, and narration.
That makes Renderforest useful when a prompt is not just meant to create one clip, but to become a finished branded video. The strongest workflow is to separate the creative brief from the scene prompts:
For example:
Create a short vertical video for a local bakery promoting a weekend croissant special. The tone should be warm and friendly. Use close-up bakery visuals, soft morning light, gentle camera movement, and space for captions. Avoid generated text inside the video.
Then refine the generated scenes and add final copy in the editor.
This keeps the prompt useful without forcing the model to solve every part of the video at once.
This table is the difference between copying prompts and actually learning to direct outputs. A good prompt writer does not just write. They diagnose.
Do not expect the first generation to be perfect. Prompting is closer to directing than typing a command.
Use this workflow:
Example iteration:
The final version is not much longer. It is just more useful.
Use these templates as starting points.
Create a [duration] [aspect ratio] product video of [product] on [surface/background]. The product [simple action or camera reveal]. Use [lighting] to emphasize [material/texture]. Camera: [shot type + movement]. Style: [brand mood]. Keep [product detail] consistent. Avoid [unwanted elements].
Create a [duration] vertical 9:16 video for [platform] showing [hook visual]. The scene should communicate [message] quickly. Use [camera movement], [lighting], and [style]. Leave space for captions. Avoid generated text.
Create a [duration] [aspect ratio] cinematic scene of [subject] [action] in [setting]. Camera: [shot size, angle, movement]. Lighting: [lighting setup]. Mood: [emotion]. Style: [visual genre]. Keep motion natural and avoid [problems].
Create a [duration] presenter-led video with [avatar description] speaking to camera. Tone: [tone]. Background: [setting]. Script: “[script].” Delivery should be [pace/emotion]. Keep gestures natural and minimal.
Create a [duration] [format] branded marketing video for [audience] about [offer/message]. Scene 1: [visual]. Scene 2: [visual]. Scene 3: [visual]. Style: [brand style]. Lighting: [lighting]. Leave clean space for text overlays. Do not generate readable text or logos.
Before spending credits, check your prompt against this list:
If the answer is “no” to more than two of these, rewrite before generating.
A good text-to-video AI prompt describes the subject, action, setting, camera movement, lighting, visual style, format, and constraints. For example: “Create a 6-second vertical video of a ceramic coffee cup on a wooden café table, steam rising slowly, close-up slow push-in, warm morning light, shallow depth of field, realistic café ad style, no text or hands.”
A good prompt is usually 40–100 words. It should be long enough to direct the scene but short enough to stay focused. If the prompt needs several scenes, split it into separate shot prompts.
Yes. Camera movement is one of the most useful prompt details. Phrases like “slow push-in,” “tracking shot,” “static tripod shot,” “close-up,” and “wide shot” help the model understand how the viewer should experience the scene.
Usually no. AI video models often distort exact letters, prices, URLs, and brand names. Ask the model to leave clean space for text, then add captions, logos, CTAs, and legal copy in the editing stage.
Use concrete details: real materials, natural lighting, simple motion, stable camera direction, and believable settings. Avoid mixing too many styles or asking for impossible actions.
Repeat the same character description in every prompt and use reference images or character references when the tool supports them. Keep clothing, hairstyle, age, and key visual traits consistent.
The biggest mistake is asking for a finished video in one vague sentence. A better approach is to generate clear individual shots, then edit them together with captions, music, logo, and final text.
Yes. Renderforest’s AI Video Generator can start from text, images, or scripts and turn them into scenes with visuals, voiceover, and editing tools. It is useful when your prompt needs to become a fuller branded video workflow rather than a single AI clip.
Effective text-to-video prompts are specific, visual, and focused. Start with one subject, give it one action, place it in a clear setting, direct the camera, define the lighting, choose one style, and add only the constraints that matter.
The best prompt does not try to make the AI do the entire production job. It gives the model a clear shot to create, then leaves captions, logos, final copy, music, and editing to the tools that handle those jobs better.
If you think like a director instead of a prompt writer, your AI videos become more consistent, more usable, and easier to turn into finished content.
Share this
Article by: Liana Ziroyan
Liana is a marketing professional with 11 years of experience in digital marketing, content, and product communication. She has a strong eye for visual storytelling and loves turning ideas into engaging campaigns that connect with audiences. With her experience across branding, creative content, and user-focused messaging, Liana enjoys finding simple, effective ways to make products feel clear, useful, and exciting.
Read all posts by Liana Ziroyan